Interactive online version:
![]()
![]()
WangchanBERTa: Getting Started Notebook
![]()
This is a developing Getting Started Notebook for WangchanBERTa. Currently it has inference methods you can easily use from HuggingFace. We will add pretraining and finetuning methods from the scripts in vistec-ai/thai2transformers.

Fork from https://colab.research.google.com/drive/1Kbk6sBspZLwcnOE61adAQo30xxqOQ9ko#scrollTo=n5IaCot9b3cF
Installation
Install dependencies at specific versions to make sure WangchanBERTa works.
[ ]:
# Install transformers and thaixtransformers
!pip install transformers thaixtransformers
Looking in indexes: https://pypi.org/simple, https://us-python.pkg.dev/colab-wheels/public/simple/
Collecting transformers
Downloading transformers-4.30.1-py3-none-any.whl (7.2 MB)
━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━ 7.2/7.2 MB 72.5 MB/s eta 0:00:00
Requirement already satisfied: filelock in /usr/local/lib/python3.10/dist-packages (from transformers) (3.12.0)
Collecting huggingface-hub<1.0,>=0.14.1 (from transformers)
Downloading huggingface_hub-0.15.1-py3-none-any.whl (236 kB)
━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━ 236.8/236.8 kB 29.7 MB/s eta 0:00:00
Requirement already satisfied: numpy>=1.17 in /usr/local/lib/python3.10/dist-packages (from transformers) (1.22.4)
Requirement already satisfied: packaging>=20.0 in /usr/local/lib/python3.10/dist-packages (from transformers) (23.1)
Requirement already satisfied: pyyaml>=5.1 in /usr/local/lib/python3.10/dist-packages (from transformers) (6.0)
Requirement already satisfied: regex!=2019.12.17 in /usr/local/lib/python3.10/dist-packages (from transformers) (2022.10.31)
Requirement already satisfied: requests in /usr/local/lib/python3.10/dist-packages (from transformers) (2.27.1)
Collecting tokenizers!=0.11.3,<0.14,>=0.11.1 (from transformers)
Downloading tokenizers-0.13.3-cp310-cp310-manylinux_2_17_x86_64.manylinux2014_x86_64.whl (7.8 MB)
━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━ 7.8/7.8 MB 106.4 MB/s eta 0:00:00
Collecting safetensors>=0.3.1 (from transformers)
Downloading safetensors-0.3.1-cp310-cp310-manylinux_2_17_x86_64.manylinux2014_x86_64.whl (1.3 MB)
━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━ 1.3/1.3 MB 73.3 MB/s eta 0:00:00
Requirement already satisfied: tqdm>=4.27 in /usr/local/lib/python3.10/dist-packages (from transformers) (4.65.0)
Requirement already satisfied: fsspec in /usr/local/lib/python3.10/dist-packages (from huggingface-hub<1.0,>=0.14.1->transformers) (2023.4.0)
Requirement already satisfied: typing-extensions>=3.7.4.3 in /usr/local/lib/python3.10/dist-packages (from huggingface-hub<1.0,>=0.14.1->transformers) (4.5.0)
Requirement already satisfied: urllib3<1.27,>=1.21.1 in /usr/local/lib/python3.10/dist-packages (from requests->transformers) (1.26.15)
Requirement already satisfied: certifi>=2017.4.17 in /usr/local/lib/python3.10/dist-packages (from requests->transformers) (2022.12.7)
Requirement already satisfied: charset-normalizer~=2.0.0 in /usr/local/lib/python3.10/dist-packages (from requests->transformers) (2.0.12)
Requirement already satisfied: idna<4,>=2.5 in /usr/local/lib/python3.10/dist-packages (from requests->transformers) (3.4)
Installing collected packages: tokenizers, safetensors, huggingface-hub, transformers
Successfully installed huggingface-hub-0.15.1 safetensors-0.3.1 tokenizers-0.13.3 transformers-4.30.1
━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━ 355.8/355.8 kB 15.3 MB/s eta 0:00:00
Preparing metadata (setup.py) ... done
━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━ 8.9/8.9 MB 6.5 MB/s eta 0:00:00
━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━ 8.7/8.7 MB 47.6 MB/s eta 0:00:00
━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━ 43.6/43.6 kB 5.9 MB/s eta 0:00:00
Preparing metadata (setup.py) ... done
━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━ 1.3/1.3 MB 84.1 MB/s eta 0:00:00
━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━ 993.5/993.5 kB 72.5 MB/s eta 0:00:00
━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━ 110.8/110.8 kB 13.8 MB/s eta 0:00:00
Building wheel for emoji (setup.py) ... done
Building wheel for seqeval (setup.py) ... done
Looking in indexes: https://pypi.org/simple, https://us-python.pkg.dev/colab-wheels/public/simple/
Collecting thai2transformers==0.1.2
Downloading thai2transformers-0.1.2.tar.gz (27 kB)
Preparing metadata (setup.py) ... done
Building wheels for collected packages: thai2transformers
Building wheel for thai2transformers (setup.py) ... done
Created wheel for thai2transformers: filename=thai2transformers-0.1.2-py3-none-any.whl size=28115 sha256=d0f182fee94a7c129f5bd1265a3e0d2a52893384d6783d11c8bbd770ef695fac
Stored in directory: /root/.cache/pip/wheels/2c/4b/b2/a90368d80567249f258a9c58240512046afb5563d794eda4b2
Successfully built thai2transformers
Installing collected packages: thai2transformers
Successfully installed thai2transformers-0.1.2
[9]:
import numpy as np
from tqdm.auto import tqdm
import torch
from functools import partial
#transformers
from transformers import (
CamembertTokenizer,
AutoTokenizer,
AutoModel,
AutoModelForMaskedLM,
AutoModelForSequenceClassification,
AutoModelForTokenClassification,
TrainingArguments,
Trainer,
pipeline,
)
#thai2transformers
from thaixtransformers import Tokenizer
from thaixtransformers.preprocess import process_transformers
Choose Pretrained Model
In this notebook, you can choose from 5 versions of WangchanBERTa, XLMR and mBERT to perform downstream tasks with Thai datasets. The datasets are:
wangchanberta-base-att-spm-uncased(recommended) - Largest WangchanBERTa trained on 78.5GB of Assorted Thai Texts with subword tokenizer SentencePiecexlm-roberta-base- Facebook’s XLMR trained on 100 languagesbert-base-multilingual-cased- Google’s mBERT trained on 104 languageswangchanberta-base-wiki-newmm- WangchanBERTa trained on Thai Wikipedia Dump with PyThaiNLP’s word-level tokenizernewmmwangchanberta-base-wiki-syllable- WangchanBERTa trained on Thai Wikipedia Dump with PyThaiNLP’s syllabel-level tokenizersyllablewangchanberta-base-wiki-sefr- WangchanBERTa trained on Thai Wikipedia Dump with word-level tokenizerSEFRwangchanberta-base-wiki-spm- WangchanBERTa trained on Thai Wikipedia Dump with subword-level tokenizer SentencePiece
[24]:
model_names = [
'wangchanberta-base-att-spm-uncased',
'xlm-roberta-base',
'bert-base-multilingual-cased',
'wangchanberta-base-wiki-newmm',
'wangchanberta-base-wiki-syllable',
'wangchanberta-base-wiki-sefr',
'wangchanberta-base-wiki-spm',
]
# tokenizers = {
# 'wangchanberta-base-att-spm-uncased': AutoTokenizer,
# 'xlm-roberta-base': AutoTokenizer,
# 'bert-base-multilingual-cased': AutoTokenizer,
# 'wangchanberta-base-wiki-newmm': ThaiWordsNewmmTokenizer,
# 'wangchanberta-base-wiki-ssg': ThaiWordsSyllableTokenizer,
# 'wangchanberta-base-wiki-sefr': FakeSefrCutTokenizer,
# 'wangchanberta-base-wiki-spm': ThaiRobertaTokenizer,
# }
public_models = ['xlm-roberta-base', 'bert-base-multilingual-cased']
#@title Choose Pretrained Model
model_name = "airesearch/wangchanberta-base-att-spm-uncased" #@param ["airesearch/wangchanberta-base-att-spm-uncased", "xlm-roberta-base", "bert-base-multilingual-cased", "airesearch/wangchanberta-base-wiki-newmm", "airesearch/wangchanberta-base-wiki-syllable", "airesearch/wangchanberta-base-wiki-sefr", "airesearch/wangchanberta-base-wiki-spm"]
#create tokenizer
tokenizer = Tokenizer(model_name).from_pretrained(
f'{model_name}' if model_name not in public_models else f'{model_name}',
revision='main',
model_max_length=416,)
The tokenizer class you load from this checkpoint is not the same type as the class this function is called from. It may result in unexpected tokenization.
The tokenizer class you load from this checkpoint is 'RobertaTokenizer'.
The class this function is called from is 'ThaiWordsNewmmTokenizer'.
The tokenizer class you load from this checkpoint is not the same type as the class this function is called from. It may result in unexpected tokenization.
The tokenizer class you load from this checkpoint is 'RobertaTokenizer'.
The class this function is called from is 'ThaiWordsNewmmTokenizer'.
Masked Token Prediction
The simplest task for WangchanBERTa is the task it was trained on, that is, masked token prediction. The model will try to predict the masked token in a given sequence. For example:
Question: วังจันทร์วัลเลย์ ตั้งอยู่บนพื้นที่ 3,454
<mask>ของอำเภอวังจันทร์ จังหวัดระยอง
Answer [
ไร่,ตารางเมตร,กิโลเมตร,ตารางวา,ไมล์]
We can use this to create more data for smaller datasets by substituting parts of the sequences; for instance, if you have 1,000 sequences, you can mask parts of each sequence and generate another 10,000 sentences for traning set. This has been proven to increase downstream performance such as the case of AUG-BERT for English.
[25]:
#pipeline
fill_mask = pipeline(task='fill-mask',
tokenizer=tokenizer,
model = f'{model_name}' if model_name not in public_models else f'{model_name}',
revision = 'main',)
[26]:
input_text = '\u0E02\u0E2D\u0E40\u0E07\u0E34\u0E19\u0E01\u0E39\u0E49\u003Cmask>\u0E2B\u0E19\u0E48\u0E2D\u0E22' #@param ['โครงการมีระยะทางทั้งหมด 114.3 <mask> มีจำนวนสถานี 36 สถานี เป็นเส้นทางหลักในแนวเหนือ–ใต้ ตามแนวทางรถไฟเดิมของการรถไฟแห่งประเทศไทย', 'วังจันทร์วัลเลย์ ตั้งอยู่บนพื้นที่ 3,454 <mask> ของอำเภอวังจันทร์ จังหวัดระยอง', 'ข้าวหน้าเนื้อ หรือเรียกเป็นภาษา<mask>ว่ากิวด้ง (Gyūdon)','จะไปเป็น<mask>โดดเด่นบนฟากฟ้า จะไปไขว่ขว้าเอามาดั่งใจฝัน', 'เช็คยอด<mask>', 'ขอเงินกู้<mask>หน่อย','กด<mask>ไม่ได้'] {allow-input: true}
preprocess_input_text = True #@param {type:"boolean"}
if preprocess_input_text:
if model_name not in public_models:
input_text = process_transformers(input_text)
#if the sequence is too short, it needs padding
def fill_mask_pad(input_text):
return fill_mask(input_text+'<pad>')
#infer
fill_mask_pad(input_text)
[26]:
[{'score': 0.513759434223175,
'token': 4263,
'token_str': 'ราม',
'sequence': 'ขอเงินกู้รามหน่อย'},
{'score': 0.05489557236433029,
'token': 552,
'token_str': 'แม่',
'sequence': 'ขอเงินกู้แม่หน่อย'},
{'score': 0.0474877767264843,
'token': 125,
'token_str': 'ดี',
'sequence': 'ขอเงินกู้ดีหน่อย'},
{'score': 0.037654660642147064,
'token': 5901,
'token_str': 'สะดวก',
'sequence': 'ขอเงินกู้สะดวกหน่อย'},
{'score': 0.026551486924290657,
'token': 1913,
'token_str': 'นา',
'sequence': 'ขอเงินกู้นาหน่อย'}]
Sequence Classification
Multi-class sequence classification datasets such as: * wisesight_sentiment - sentiment analysis from social media data provided by Wisesight * wongnai_reviews - review classification from Wongnai.com
Pretrained Multi-class Classifiers - Wisesight Sentiment and Wongnai Reviews
You can use our state-of-the-art finetuned WangchanBERTa for these tasks right away with:
[27]:
#@title Choose Multi-class Classification Dataset
dataset_name = "wisesight_sentiment" #@param ['wisesight_sentiment','wongnai_reviews']
#pipeline
classify_multiclass = pipeline(task='sentiment-analysis',
tokenizer=tokenizer,
model = f'{model_name}' if model_name not in public_models else f'{model_name}',
revision = f'finetuned@{dataset_name}')
[28]:
input_text = '\u0E40\u0E04\u0E22\u0E1A\u0E49\u0E32\u0E40\u0E2D\u0E47\u0E21\u0E40\u0E04\u0E01\u0E31\u0E1A\u0E41\u0E21\u0E48 \u0E01\u0E34\u0E19\u0E2D\u0E32\u0E17\u0E34\u0E15\u0E22\u0E4C\u0E25\u0E303-4 \u0E27\u0E31\u0E19\u0E15\u0E34\u0E14 \u0E42\u0E04\u0E15\u0E23\u0E2B\u0E19\u0E31\u0E01\u0E41\u0E25\u0E30\u0E42\u0E04\u0E15\u0E23\u0E40\u0E1B\u0E25\u0E37\u0E2D\u0E07\u0E07\u0E07\u0E07' #@param ['อยากกินวะแก ซื้อมาให้หน่อยจิ', 'ขอบคุณแกมาก โคตรบ้าเลย', 'ฟอร์ด บุกตลาด อีวี ในอินเดีย #prachachat #ตลาดรถยนต์', 'สั่งไป2 เมนู คือมัชฉะลาเต้ร้อน กับ ไอศครีมชาเขียว มัชฉะลาเต้ร้อน รสชาเขียวเข้มข้น หอม มัน แต่ไม่กลมกล่อม มันจืดแบบจืดสนิท ส่วนไอศครีมชาเขียว ทานแล้วรสมันออกใบไม้ๆมากกว่าชาเขียว แล้วก็หวานไป โดยรวมแล้วเฉยมากก ดีแค่รสชาเขียวเข้ม มีน้ำเปล่าบริการฟรี','เคยบ้าเอ็มเคกับแม่ กินอาทิตย์ละ3-4 วันติด โคตรหนักและโคตรเปลืองงงง'] {allow-input: true}
preprocess_input_text = True #@param {type:"boolean"}
if preprocess_input_text:
if model_name not in public_models:
input_text = process_transformers(input_text)
#infer
classify_multiclass(input_text)
[28]:
[{'label': 'neg', 'score': 0.892067551612854}]
Token Classification
We have state-of-the-art named entity recognition taggers based on both ThaiNER and LST20.
Pretrained Token Classifiers - ThaiNER and LST20
[29]:
#@title Choose Token Classification Dataset
dataset_name = "thainer" #@param ['thainer','lst20']
#pipeline
classify_tokens = pipeline(task='ner',
tokenizer=tokenizer,
model = f'{model_name}' if model_name not in public_models else f'{model_name}',
revision = f'finetuned@{dataset_name}-ner',
ignore_labels=[],
grouped_entities=True)
/usr/local/lib/python3.8/dist-packages/transformers/pipelines/token_classification.py:169: UserWarning: `grouped_entities` is deprecated and will be removed in version v5.0.0, defaulted to `aggregation_strategy="simple"` instead.
warnings.warn(
[30]:
input_text = '\u0E42\u0E23\u0E07\u0E40\u0E23\u0E35\u0E22\u0E19\u0E2A\u0E27\u0E19\u0E01\u0E38\u0E2B\u0E25\u0E32\u0E1A\u0E40\u0E1B\u0E47\u0E19\u0E42\u0E23\u0E07\u0E40\u0E23\u0E35\u0E22\u0E19\u0E17\u0E35\u0E48\u0E14\u0E35 \u0E41\u0E15\u0E48\u0E44\u0E21\u0E48\u0E21\u0E35\u0E2A\u0E27\u0E19\u0E01\u0E38\u0E2B\u0E25\u0E32\u0E1A' #@param ['โรงเรียนสวนกุหลาบเป็นโรงเรียนที่ดี แต่ไม่มีสวนกุหลาบ', 'แดงเดือดรอบสอง ลิเวอร์พูล บุกเยือน แมนฯ ยูไนเต็ด', 'จีน-อินเดียเสี่ยงสูญเสียจากภัยธรรมชาติมากสุด', 'ทำให้ประชาชนกว่า 10,000 คน ต้องอพยพออกจากพื้นที่ อิทธิพลของพายุยังทำให้บ้านเรือนเกือบ 9,700 หลังพังถล่มลงมา สร้างความเสียหายคิดเป็นมูลค่า 450 ล้านหยวน','กทช.เตรียมทดลองประมูล 3จี 25 ก.ค.นี้']
preprocess_input_text = True #@param {type:"boolean"}
if preprocess_input_text:
if model_name not in public_models:
input_text = process_transformers(input_text)
#infer
classify_tokens(input_text)
[30]:
[{'entity_group': 'ORGANIZATION',
'score': 0.97664016,
'word': 'โรงเรียนสวนกุหลาบ',
'start': None,
'end': None},
{'entity_group': 'O',
'score': 0.99976474,
'word': 'เป็นโรงเรียนที่ดี<_>แต่ไม่มีสวนกุหลาบ',
'start': None,
'end': None}]
Document Vectors
If the HuggingFace finetuners do not have what you are looking for, or you want to do something less traditional such as clustering using document vectors or simply use the document vectors for other classifiers such as logistic regression, random forest and gradient boosting. 
Image by [@mrpeerat](https://github.com/mrpeerat)
Feature Extraction
We can use the outputs of WangchanBERTa (or any transformer-based models) as document vectors as an example by BramVanroy.

[31]:
#pipeline
feature_extractor = pipeline(task='feature-extraction',
tokenizer=tokenizer,
model = f'{model_name}' if model_name not in public_models else f'{model_name}',
revision = 'main')
def extract_last_k_tokens(input_text, feature_extractor, last_k=4):
hidden_states = feature_extractor(input_text)[0]
last_k_tokens = [hidden_states[i] for i in [-i for i in range(1,last_k+1)]]
concatenated_hidden_states = sum(last_k_tokens, [])
return np.array(concatenated_hidden_states)
def _extract_last_k_layers(input_text, model, tokenizer, last_k=4,
aggregator_fn=partial(torch.sum, dim=0)):
inputs = tokenizer(input_text, return_tensors="pt")
with torch.no_grad():
outputs = model(**inputs, output_hidden_states=True)
hidden_states = outputs.hidden_states
# select the hidden states of the first token (<s>).
concatenated_hidden_states = torch.cat([hidden_states[-i][:,0] for i in range(1, last_k + 1)])
aggregated_hidden_states = aggregator_fn(concatenated_hidden_states)
return aggregated_hidden_states
# Specify model and tokenizer for `extract_last_k_layers` function.
extract_last_k_layers = partial(_extract_last_k_layers,
model=AutoModel.from_pretrained(
pretrained_model_name_or_path=f'{model_name}' if model_name not in public_models else f'{model_name}',
revision='main'),
tokenizer=tokenizer)
Some weights of the model checkpoint at airesearch/wangchanberta-base-wiki-newmm were not used when initializing RobertaModel: ['lm_head.decoder.bias', 'lm_head.layer_norm.weight', 'lm_head.layer_norm.bias', 'lm_head.bias', 'lm_head.decoder.weight', 'lm_head.dense.bias', 'lm_head.dense.weight']
- This IS expected if you are initializing RobertaModel from the checkpoint of a model trained on another task or with another architecture (e.g. initializing a BertForSequenceClassification model from a BertForPreTraining model).
- This IS NOT expected if you are initializing RobertaModel from the checkpoint of a model that you expect to be exactly identical (initializing a BertForSequenceClassification model from a BertForSequenceClassification model).
Some weights of RobertaModel were not initialized from the model checkpoint at airesearch/wangchanberta-base-wiki-newmm and are newly initialized: ['roberta.pooler.dense.weight', 'roberta.pooler.dense.bias']
You should probably TRAIN this model on a down-stream task to be able to use it for predictions and inference.
Some weights of the model checkpoint at airesearch/wangchanberta-base-wiki-newmm were not used when initializing RobertaModel: ['lm_head.decoder.bias', 'lm_head.layer_norm.weight', 'lm_head.layer_norm.bias', 'lm_head.bias', 'lm_head.decoder.weight', 'lm_head.dense.bias', 'lm_head.dense.weight']
- This IS expected if you are initializing RobertaModel from the checkpoint of a model trained on another task or with another architecture (e.g. initializing a BertForSequenceClassification model from a BertForPreTraining model).
- This IS NOT expected if you are initializing RobertaModel from the checkpoint of a model that you expect to be exactly identical (initializing a BertForSequenceClassification model from a BertForSequenceClassification model).
Some weights of RobertaModel were not initialized from the model checkpoint at airesearch/wangchanberta-base-wiki-newmm and are newly initialized: ['roberta.pooler.dense.weight', 'roberta.pooler.dense.bias']
You should probably TRAIN this model on a down-stream task to be able to use it for predictions and inference.
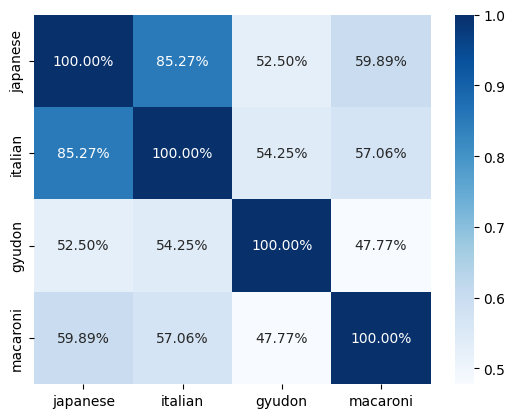
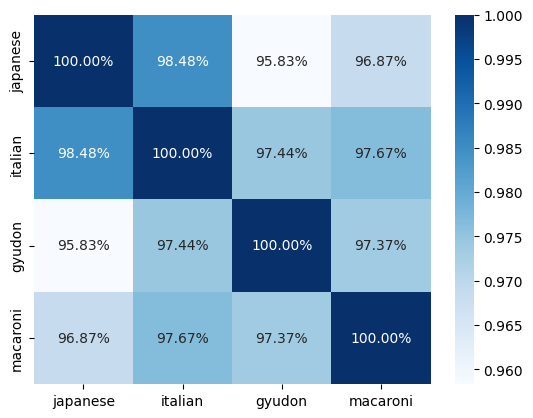
You can see I like Japanese food and I like gyudon (as well as I like Italian food and I like macaroni) have high cosine similarity as they are considered “close” by WangchanBERTa.
[32]:
#@title Show similarity between Food and Country (Last $k$ tokens)
#@markdown Note: The sentence-level vector is obtained by aggregating (via summation) last 3 token represnetaitons of the last layer
text1 = 'ฉันชอบกินอาหารญี่ปุ่น' #@param {type:"raw"}
text2 = 'ฉันชอบกินอาหารอิตาเลียน' #@param {type:"raw"}
text3 = 'ฉันชอบกินกิวด้ง' #@param {type:"raw"}
text4 = 'ฉันชอบกินมักกะโรนี' #@param {type:"raw"}
t1 = extract_last_k_tokens(text1, feature_extractor)[None,:]
t2 = extract_last_k_tokens(text2, feature_extractor)[None,:]
t3 = extract_last_k_tokens(text3, feature_extractor)[None,:]
t4 = extract_last_k_tokens(text4, feature_extractor)[None,:]
ts = np.concatenate([t1,t2,t3,t4],0)
from sklearn.metrics.pairwise import cosine_similarity
import seaborn as sns
sim_matrix = cosine_similarity(ts,ts)
sns.heatmap(sim_matrix, annot=True,
fmt='.2%', cmap='Blues',
xticklabels=['japanese','italian','gyudon','macaroni'],
yticklabels=['japanese','italian','gyudon','macaroni'])
[32]:
<Axes: >
[33]:
#@title Show similarity between Food and Country (Last $k$ layers)
#@markdown Note: The Sentence-level vector is obtained by aggregating (via summation) of the BOS token represnetaiton (\<s\>) from the last $k$ Transformer Encoder layers.
text1 = 'ฉันชอบกินอาหารญี่ปุ่น' #@param {type:"raw"}
text2 = 'ฉันชอบกินอาหารอิตาเลียน' #@param {type:"raw"}
text3 = 'ฉันชอบกินกิวด้ง' #@param {type:"raw"}
text4 = 'ฉันชอบกินมักกะโรนี' #@param {type:"raw"}
t1 = extract_last_k_layers(text1)[None,:]
t2 = extract_last_k_layers(text2)[None,:]
t3 = extract_last_k_layers(text3)[None,:]
t4 = extract_last_k_layers(text4)[None,:]
ts = np.concatenate([t1,t2,t3,t4],0)
from sklearn.metrics.pairwise import cosine_similarity
import seaborn as sns
sim_matrix = cosine_similarity(ts,ts)
sns.heatmap(sim_matrix, annot=True,
fmt='.2%', cmap='Blues',
xticklabels=['japanese','italian','gyudon','macaroni'],
yticklabels=['japanese','italian','gyudon','macaroni'])
[33]:
<Axes: >
Zero-shot Text Classification
Zero-shot text classification is a fancy way of saying “do similarity search with a given set of labels based on pretrained model outputs”. It maybe useful when you do not have any training data to finetune at all. Here is how you can do it.
Updated on Friday 26 March 2021: We have released WanchanBERTa, XLMR and mBERT models finetuned on XNLI dataset ( Thai sentence pairs). The finetuned model checkpoints are stored under the branch named finetuned@xnli_th in our organization repositories (available at Huggingface Model Hub (https://huggingface.co/airesearch)).
[34]:
#pipeline
zero_classify = pipeline(task='zero-shot-classification',
tokenizer=tokenizer,
model=AutoModelForSequenceClassification.from_pretrained(
f'{model_name}' if model_name not in public_models else f'{model_name}-finetuned',
revision='finetuned@xnli_th')
)
[35]:
input_text = "\u0E17\u0E35\u0E21\u0E44\u0E1A\u0E40\u0E14\u0E19\u0E2B\u0E32\u0E23\u0E37\u0E2D\u0E01\u0E31\u0E1A\u0E0D\u0E35\u0E48\u0E1B\u0E38\u0E48\u0E19 \u0E01\u0E23\u0E30\u0E0A\u0E31\u0E1A\u0E04\u0E27\u0E32\u0E21\u0E40\u0E1B\u0E47\u0E19\u0E1E\u0E31\u0E19\u0E18\u0E21\u0E34\u0E15\u0E23" #@param ["SCB 10X \u0E23\u0E48\u0E27\u0E21\u0E25\u0E07\u0E17\u0E38\u0E19\u0E43\u0E19 BlockFi Startup \u0E14\u0E49\u0E32\u0E19 Digital Asset", "\u0E2D\u0E32\u0E40\u0E1A\u0E30\u0E1B\u0E23\u0E31\u0E1A\u0E04\u0E13\u0E30\u0E23\u0E31\u0E10\u0E21\u0E19\u0E15\u0E23\u0E35\u0E0D\u0E35\u0E48\u0E1B\u0E38\u0E48\u0E19 \u0E15\u0E31\u0E49\u0E07 \u201C\u0E23\u0E21\u0E15.\u0E01\u0E25\u0E32\u0E42\u0E2B\u0E21\u201D \u0E04\u0E19\u0E43\u0E2B\u0E21\u0E48", "WangchanBERTa \u0E42\u0E21\u0E40\u0E14\u0E25\u0E1B\u0E23\u0E30\u0E21\u0E27\u0E25\u0E1C\u0E25\u0E20\u0E32\u0E29\u0E32\u0E44\u0E17\u0E22\u0E17\u0E35\u0E48\u0E43\u0E2B\u0E0D\u0E48\u0E41\u0E25\u0E30\u0E01\u0E49\u0E32\u0E27\u0E2B\u0E19\u0E49\u0E32\u0E17\u0E35\u0E48\u0E2A\u0E38\u0E14\u0E43\u0E19\u0E02\u0E13\u0E30\u0E19\u0E35\u0E49", "\u201CWhere We Belong\" \u0E04\u0E27\u0E49\u0E32\u0E20\u0E32\u0E1E\u0E22\u0E19\u0E15\u0E23\u0E4C\u0E22\u0E2D\u0E14\u0E40\u0E22\u0E35\u0E48\u0E22\u0E21 \u0E2A\u0E38\u0E1E\u0E23\u0E23\u0E13\u0E2B\u0E07\u0E2A\u0E4C\u0E04\u0E23\u0E31\u0E49\u0E07\u0E17\u0E35\u0E48 29", "\u0E17\u0E35\u0E21\u0E44\u0E1A\u0E40\u0E14\u0E19\u0E2B\u0E32\u0E23\u0E37\u0E2D\u0E01\u0E31\u0E1A\u0E0D\u0E35\u0E48\u0E1B\u0E38\u0E48\u0E19 \u0E01\u0E23\u0E30\u0E0A\u0E31\u0E1A\u0E04\u0E27\u0E32\u0E21\u0E40\u0E1B\u0E47\u0E19\u0E1E\u0E31\u0E19\u0E18\u0E21\u0E34\u0E15\u0E23", "\u0E19\u0E31\u0E01\u0E27\u0E34\u0E08\u0E31\u0E22\u0E19\u0E32\u0E42\u0E19\u0E40\u0E17\u0E04\u0E42\u0E19\u0E42\u0E25\u0E22\u0E35 \u0E08\u0E32\u0E01\u0E2A\u0E16\u0E32\u0E1A\u0E31\u0E19\u0E27\u0E34\u0E17\u0E22\u0E2A\u0E34\u0E23\u0E34\u0E40\u0E21\u0E18\u0E35 \u0E1C\u0E39\u0E49\u0E04\u0E34\u0E14\u0E04\u0E49\u0E19\u0E41\u0E1A\u0E15\u0E40\u0E15\u0E2D\u0E23\u0E35\u0E48\u0E08\u0E32\u0E01\u0E27\u0E31\u0E2A\u0E14\u0E38\u0E01\u0E23\u0E32\u0E1F\u0E35\u0E19 \u0E04\u0E27\u0E49\u0E32\u0E23\u0E32\u0E07\u0E27\u0E31\u0E25\u0E19\u0E31\u0E01\u0E27\u0E34\u0E17\u0E22\u0E32\u0E28\u0E32\u0E2A\u0E15\u0E23\u0E4C\u0E14\u0E35\u0E40\u0E14\u0E48\u0E19 \u0E1B\u0E23\u0E30\u0E08\u0E33\u0E1B\u0E35 2562 ", "\u0E1E\u0E34\u0E1E\u0E34\u0E18\u0E20\u0E31\u0E13\u0E11\u0E4C\u0E1D\u0E23\u0E31\u0E48\u0E07\u0E40\u0E28\u0E2A\u0E40\u0E1C\u0E22\u0E41\u0E1E\u0E23\u0E48\u0E44\u0E1F\u0E25\u0E4C\u0E14\u0E34\u0E08\u0E34\u0E17\u0E31\u0E25\u0E20\u0E32\u0E1E\u0E27\u0E32\u0E14 \u0E20\u0E32\u0E1E\u0E16\u0E48\u0E32\u0E22 \u0E41\u0E25\u0E30\u0E20\u0E32\u0E1E\u0E1B\u0E23\u0E30\u0E01\u0E2D\u0E1A\u0E2B\u0E19\u0E31\u0E07\u0E2A\u0E37\u0E2D\u0E43\u0E19\u0E2D\u0E14\u0E35\u0E15 \u0E23\u0E27\u0E21\u0E01\u0E27\u0E48\u0E32 1 \u0E41\u0E2A\u0E19\u0E23\u0E39\u0E1B "] {allow-input: true}
preprocess_input_text = True #@param {type:"boolean"}
if preprocess_input_text:
if model_name not in public_models:
input_text = process_transformers(input_text)
#infer
zero_classify(input_text,
candidate_labels=['เศรษฐกิจ-ธุรกิจ','การเมือง',
'เทคโนโลยี', 'ศิลปะ-บันเทิง'],
hypothesis_template='พาดหัวข่าวนี้้เกี่ยวกับ{}')
[35]:
{'sequence': 'ทีมไบเดนหารือกับญี่ปุ่น<_>กระชับความเป็นพันธมิตร',
'labels': ['การเมือง', 'เทคโนโลยี', 'เศรษฐกิจ-ธุรกิจ', 'ศิลปะ-บันเทิง'],
'scores': [0.34431710839271545,
0.3195861279964447,
0.18645761907100677,
0.14963914453983307]}