Interactive online version:
![]()
![]()
Wisesight Sentiment Analysis
This notebook details the steps taken to create a sentiment analyzer using data from Wisesight Sentiment Corpus. Evaluation metric is overall accuracy across negative, positive, neutral and question classes. We give examples using logistic regression and ULMFit.
The results for logistic regression, fastText, ULMFit, ULMFit with semi-supervised data are as follows:
Model |
Public Accuracy |
Private Accuracy |
|---|---|---|
Logistic Regression |
0.72781 |
0.7499 |
fastText |
0.63144 |
0.6131 |
ULMFit |
0.71259 |
0.74194 |
ULMFit Semi-supervised |
0.73119 |
0.75859 |
ULMFit Semi-supervised Repeated One Time |
0.73372 |
0.75968 |
For more information about the Kaggle competition, which this notebook based upon, see 1st Place Solution.
For more updated version of data, including a tokenized
wisesight-1000evaluation set, see Wisesight Sentiment Corpus.
[2]:
# #uncomment if you are running from google colab
# !pip install sklearn_crfsuite
# !pip install emoji
# !pip install https://github.com/PyThaiNLP/pythainlp/archive/dev.zip
# !pip install fastai
# !wget https://github.com/PyThaiNLP/wisesight-sentiment/archive/master.zip
# !unzip master.zip
# !mkdir wisesight_data; ls
# !cd wisesight-sentiment-master/kaggle-competition; ls
[21]:
#snippet to install thai font in matplotlib from https://gist.github.com/korakot/9d7f5db632351dc92607fdec72a4953f
import matplotlib
!wget https://github.com/Phonbopit/sarabun-webfont/raw/master/fonts/thsarabunnew-webfont.ttf
!cp thsarabunnew-webfont.ttf /usr/local/lib/python3.6/dist-packages/matplotlib/mpl-data/fonts/ttf/
!cp thsarabunnew-webfont.ttf /usr/share/fonts/truetype/
matplotlib.font_manager._rebuild()
matplotlib.rc('font', family='TH Sarabun New')
[6]:
%load_ext autoreload
%autoreload 2
import numpy as np
import pandas as pd
from pythainlp import word_tokenize
from tqdm import tqdm_notebook
from pythainlp.ulmfit import process_thai
#viz
import matplotlib.pyplot as plt
import seaborn as sns
The autoreload extension is already loaded. To reload it, use:
%reload_ext autoreload
Text Processor for Logistic Regression
pythainlp.ulmfit.process_thai contains text cleaning rules with the default aimed for sparse models like bag of words. It contains pre_rules applied before tokenization and post_rules applied after.
[57]:
?process_thai
[59]:
from pythainlp.ulmfit import *
process_thai("บ้านนนนน ()อยู่นานนานนาน 😂🤣😃😄😅 PyThaiNLP amp; www.google.com")
[59]:
['บ้าน',
'xxrep',
' ',
'อยู่',
'xxwrep',
'นาน',
'😂',
'🤣',
'😃',
'😄',
'😅',
'pythainlp',
'&',
'xxurl']
Process Text Files to CSVs
[7]:
with open("wisesight-sentiment-master/kaggle-competition/train.txt") as f:
texts = [line.strip() for line in f.readlines()]
with open("wisesight-sentiment-master/kaggle-competition/train_label.txt") as f:
categories = [line.strip() for line in f.readlines()]
all_df = pd.DataFrame({"category":categories, "texts":texts})
all_df.to_csv('all_df.csv',index=False)
all_df.shape
[7]:
(24063, 2)
[8]:
with open("wisesight-sentiment-master/kaggle-competition/test.txt") as f:
texts = [line.strip() for line in f.readlines()]
test_df = pd.DataFrame({"category":"test", "texts":texts})
test_df.shape
[8]:
(2674, 2)
Load Data
[9]:
all_df["processed"] = all_df.texts.map(lambda x: "|".join(process_thai(x)))
all_df["wc"] = all_df.processed.map(lambda x: len(x.split("|")))
all_df["uwc"] = all_df.processed.map(lambda x: len(set(x.split("|"))))
test_df["processed"] = test_df.texts.map(lambda x: "|".join(process_thai(x)))
test_df["wc"] = test_df.processed.map(lambda x: len(x.split("|")))
test_df["uwc"] = test_df.processed.map(lambda x: len(set(x.split("|"))))
[10]:
#prevalence
all_df.category.value_counts() / all_df.shape[0]
[10]:
neu 0.544612
neg 0.255164
pos 0.178698
q 0.021527
Name: category, dtype: float64
Train-validation Split
We perform 85/15 random train-validation split. We also perform under/oversampling to balance out the classes a little.
[11]:
#when finding hyperparameters
from sklearn.model_selection import train_test_split
train_df, valid_df = train_test_split(all_df, test_size=0.15, random_state=1412)
train_df = train_df.reset_index(drop=True)
valid_df = valid_df.reset_index(drop=True)
#when actually doing it
# train_df = all_df.copy()
# valid_df = pd.read_csv('valid_df.csv')
[12]:
valid_df.head()
[12]:
| category | texts | processed | wc | uwc | |
|---|---|---|---|---|---|
| 0 | neu | เห็นคนลบแอพ viu ก็เห็นใจและเข้าใจเขานะคะ แผลมั... | เห็น|คน|ลบ|แอ|พ|viu|ก็|เห็นใจ|และ|เข้าใจ|เขา|น... | 48 | 43 |
| 1 | neu | ไปชมไม้คิวของแชมป์ และรองแชมป์ กันจ้า! .......... | ไป|ชม|ไม้|คิว|ของ|แชมป์|และ|รอง|แชมป์|กัน|จ้า|... | 43 | 41 |
| 2 | neg | กลุ่มรถซีวิคเป็นกลุ่มที่น่ารำคานมากกกกกกกกก อว... | กลุ่ม|รถ|ซีวิค|เป็น|กลุ่ม|ที่|น่า|รำ|คาน|มาก|x... | 47 | 36 |
| 3 | neu | อยากสวยเหมือนเจ้าของแบรนด์สิคะ เนย โชติกา ใบหน... | อยาก|สวย|เหมือน|เจ้าของ|แบรนด์|สิ|คะ|เนย|โชติ|... | 72 | 56 |
| 4 | neg | ข้าวโถละร้อย แพง เพราะตักเป็นจานๆละ15 เต็มที่ก... | ข้าว|โถ|ละ|ร้อย|แพง|เพราะ|ตัก|เป็น|จาน|ๆ|ละ|15... | 381 | 218 |
[13]:
#prevalence
print(train_df["category"].value_counts() / train_df.shape[0])
neu 0.544957
neg 0.253557
pos 0.180071
q 0.021415
Name: category, dtype: float64
[14]:
#prevalence
print(valid_df["category"].value_counts() / valid_df.shape[0])
neu 0.542659
neg 0.264266
pos 0.170914
q 0.022161
Name: category, dtype: float64
Logistic Regression
Create Features
[15]:
#dependent variables
y_train = train_df["category"]
y_valid = valid_df["category"]
[16]:
#text faetures
from sklearn.feature_extraction.text import TfidfVectorizer
from sklearn.linear_model import LogisticRegression
tfidf = TfidfVectorizer(tokenizer=process_thai, ngram_range=(1,2), min_df=20, sublinear_tf=True)
tfidf_fit = tfidf.fit(all_df["texts"])
text_train = tfidf_fit.transform(train_df["texts"])
text_valid = tfidf_fit.transform(valid_df["texts"])
text_test = tfidf_fit.transform(test_df["texts"])
text_train.shape, text_valid.shape
[16]:
((20453, 4614), (3610, 4614))
[17]:
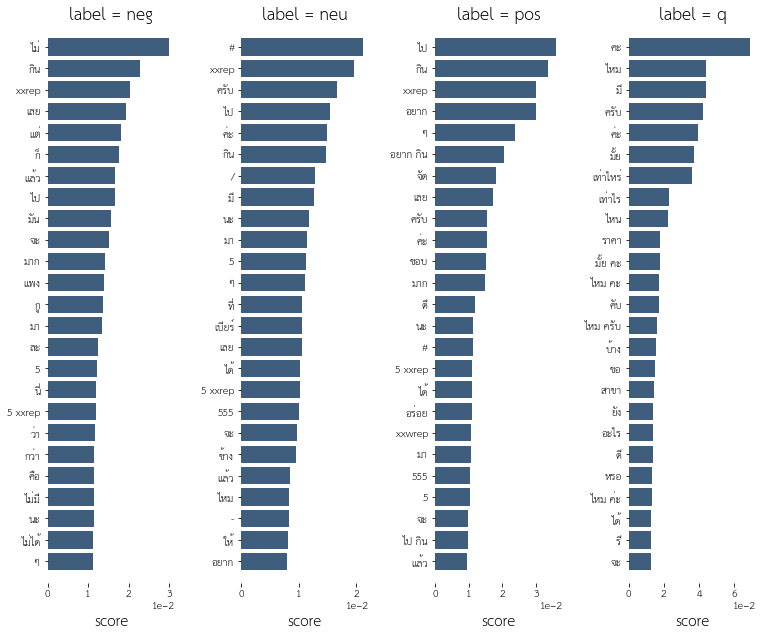
#visualize texts
from visualize import top_feats_all, plot_top_feats
features = tfidf_fit.get_feature_names()
%time ts = top_feats_all(text_train.toarray(), y_train, features)
print(ts[0].shape)
ts[0].head()
CPU times: user 448 ms, sys: 492 ms, total: 940 ms
Wall time: 938 ms
(4614, 5)
[17]:
| rank | feature | score | ngram | label | |
|---|---|---|---|---|---|
| 0 | 0 | ไม่ | 0.029990 | 1 | neg |
| 1 | 1 | กิน | 0.022852 | 1 | neg |
| 2 | 2 | xxrep | 0.020252 | 1 | neg |
| 3 | 3 | เลย | 0.019493 | 1 | neg |
| 4 | 4 | แต่ | 0.018153 | 1 | neg |
[20]:
%time plot_top_feats(ts)
CPU times: user 1.36 s, sys: 852 ms, total: 2.21 s
Wall time: 862 ms
[73]:
#word count and unique word counts; actually might not be so useful
from sklearn.preprocessing import StandardScaler
scaler = StandardScaler()
scaler_fit = scaler.fit(all_df[["wc","uwc"]].astype(float))
print(scaler_fit.mean_, scaler_fit.var_)
num_train = scaler_fit.transform(train_df[["wc","uwc"]].astype(float))
num_valid = scaler_fit.transform(valid_df[["wc","uwc"]].astype(float))
num_test = scaler_fit.transform(test_df[["wc","uwc"]].astype(float))
num_train.shape, num_valid.shape
[21.96529942 18.22744462] [1151.47512883 513.46009207]
[73]:
((20453, 2), (3610, 2))
[74]:
#concatenate text and word count features
X_train = np.concatenate([num_train,text_train.toarray()],axis=1)
X_valid = np.concatenate([num_valid,text_valid.toarray()],axis=1)
X_test = np.concatenate([num_test,text_test.toarray()],axis=1)
X_train.shape, X_valid.shape
[74]:
((20453, 4616), (3610, 4616))
Fit Model
[75]:
#fit logistic regression models
model = LogisticRegression(C=2., penalty="l2", solver="liblinear", dual=False, multi_class="ovr")
model.fit(X_train,y_train)
model.score(X_valid,y_valid)
[75]:
0.7324099722991689
See Results
[76]:
probs = model.predict_proba(X_valid)
probs_df = pd.DataFrame(probs)
probs_df.columns = model.classes_
probs_df["preds"] = model.predict(X_valid)
probs_df["category"] = valid_df.category
probs_df["texts"] = valid_df.texts
probs_df["processed"] = valid_df.processed
probs_df["wc"] = valid_df.wc
probs_df["uwc"] = valid_df.uwc
probs_df["hit"] = (probs_df.preds==probs_df.category)
probs_df.to_csv("probs_df_linear.csv", index=False)
[77]:
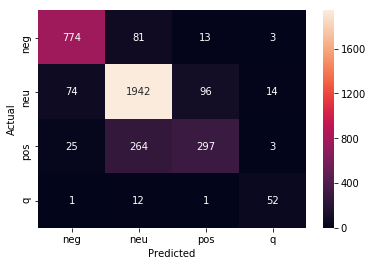
from sklearn.metrics import confusion_matrix
conf_mat = confusion_matrix(probs_df.category,probs_df.preds)
print(model.score(X_valid,y_valid))
sns.heatmap(conf_mat, annot=True, fmt="d",
xticklabels=model.classes_, yticklabels=model.classes_)
plt.ylabel("Actual")
plt.xlabel("Predicted")
plt.show()
0.7324099722991689
ULMFit Model
[79]:
from fastai.text import *
from fastai.callbacks import CSVLogger, SaveModelCallback
from pythainlp.ulmfit import *
model_path = "wisesight_data/"
all_df = pd.read_csv("all_df.csv")
train_df, valid_df = train_test_split(all_df, test_size=0.15, random_state=1412)
Finetune Language Model
[ ]:
tt = Tokenizer(tok_func=ThaiTokenizer, lang="th", pre_rules=pre_rules_th, post_rules=post_rules_th)
processor = [TokenizeProcessor(tokenizer=tt, chunksize=10000, mark_fields=False),
NumericalizeProcessor(vocab=None, max_vocab=60000, min_freq=2)]
data_lm = (TextList.from_df(all_df, model_path, cols="texts", processor=processor)
.split_by_rand_pct(valid_pct = 0.01, seed = 1412)
.label_for_lm()
.databunch(bs=48))
data_lm.sanity_check()
data_lm.save('wisesight_lm.pkl')
[32]:
data_lm.sanity_check()
len(data_lm.train_ds), len(data_lm.valid_ds)
[32]:
(23823, 240)
[33]:
config = dict(emb_sz=400, n_hid=1550, n_layers=4, pad_token=1, qrnn=False, tie_weights=True, out_bias=True,
output_p=0.25, hidden_p=0.1, input_p=0.2, embed_p=0.02, weight_p=0.15)
trn_args = dict(drop_mult=1., clip=0.12, alpha=2, beta=1)
learn = language_model_learner(data_lm, AWD_LSTM, config=config, pretrained=False, **trn_args)
#load pretrained models
learn.load_pretrained(**_THWIKI_LSTM)
[33]:
LanguageLearner(data=TextLMDataBunch;
Train: LabelList (23823 items)
x: LMTextList
xxbos ประเทศ เรา ผลิต และ ส่งออก ยาสูบ เยอะ สุด ใน โลก จิง ป่าว คับ,xxbos คะ,xxbos อิ เหี้ย ออม ทำ กู อยาก กิน เอ็ม เค,xxbos xxwrep 2 😅,xxbos สวัสดี วัน พุธ แนน อะไร นะ
y: LMLabelList
,,,,
Path: wisesight_data;
Valid: LabelList (240 items)
x: LMTextList
xxbos เห็น คน ลบ แอ พ viu ก็ เห็นใจ และ เข้าใจ เขา นะคะ แผล มัน ยัง ใหม่ แถม อารมณ์ ยิ่ง โดน xxunk ง่าย อยู่ นี่ เนอะ 5 xxrep 7 ส่วน ทาง นี้ ก็ กอด netflix แน่น มาก เธอ อย่า ทำร้าย เรา นะ เรา รู้ เธอ ไม่ ทำร้าย เรา แน่นอน,xxbos ไป ชม ไม้ คิว ของ แชมป์ และ รอง แชมป์ กัน จ้า ! . xxrep 32 เก็บตก จาก การแข่งขัน แสงโสม สนุกเกอร์ 6 แดง โอเพ่น ประจำปี 2560 สนาม ที่ 2 ณ มัง กี้ สนุกเกอร์ คลับ ซอย โชค ชัย 4 ลาดพร้าว เมื่อ วันที่ 12 ต.ค. 60,xxbos กลุ่ม รถ ซีวิค เป็น กลุ่ม ที่ น่า รำ คาน มาก xxrep 9 อวด รถ กัน ได้ ทุก วินาที อวด ทำไม มึง ก็ ใช้ รถ เหมือนกัน ทุกคน ละ ก็ พวก xxunk ที่ บอ กว่า อวด รถ แต่ ถ่าย นม ตัวเอง ชัด ละ รถ เบลอ นี่ คือ ? xxrep 5 ,xxbos อยาก สวย เหมือน เจ้าของ แบรนด์ สิ คะ เนย โชติ กา ใบหน้า สวย ใส xxunk แม้ แต่งหน้า นี่ ขนาด เป็น คุณแม่ แล้ว นะเนี่ย ก็ ยัง สวย ไม่ xxunk ผ่าน ไป กี่ ปี ๆ ก็ ไม่ เปลี่ยน ผิว ดี๊ ดี ความ สวย . เรา สร้าง เอง ได้ ด้วยตัวเอง ถ้า ได้ ใช้ มาส ์กโช ต้อง สวย เหมือน โชติ กา แน่นอน ค่ะ # มาส ์กโช สวย ข้ามคืน # cho _ cosmetics # daradaily # ดารา เดลี่,xxbos ข้าว โถ ละ ร้อย แพง เพราะ ตัก เป็น จาน ๆ ละ 15 เต็มที่ ก็ 5 จาน คนไทย ต้อง กินข้าว ประเทศ xxunk ข้าว กินข้าว ในประเทศ ตัวเอง หม้อ เป็น ร้อย เป็นลม ดีกว่า ค่า ฉะ xxunk ถุง 5 โล ไม่ เกิน 200 เป็น ข้าว มะลิ ไก่ นี่ ไม่รู้ ว่า เป็นตัว หรือเปล่า แต่ ถ้า ตัว ละ 250 บาท แพง ไก่ย่าง ขาย 140 - 160 มี เยอะแยะ ยัง ได้ กำไร แพง สุด ไม่ ควร xxunk 200 ข้าวผัด ปู จาน ใหญ่ 300 ร้อย แพง ถ้า ผัด เป็น จาน ๆ ละ 50 ผัด 4 จาน ก็ เต็ม ถาด ใหญ่ แล้ว ส่วน เครื่อง ดืม ด้านบน อะไร 80 ถ้า เป็น ชาเย็น แพง มาก น้ำ ดืม ขวด ใหญ่ ขวด ละ 50 แพง บ้าน เรา เมืองร้อน อย่า เห็นแก่ตัว 30 ก็ พอแล้ว คน ต้อง ซื้อ เยอะ เบียร์ ช้าง ขวด ละ 120 กำไร xxunk น่าเกลียด มา 3 ขวด 360 แพง xxunk ขวด ใหญ่ ก็ แพง แต่ น้ำแข็ง พอได้ เพราะ อากาศ บ้าน เรา ร้อน ละลาย ง่าย อันนี้ พอ เข้าใจ คน ขาย แต่ ทะเล เผา ทะเล ลวก ไม่เห็น หน้าตา ว่า มี อะไร บ้าง ก็ กุ้ง หมึก ปู xxunk 300 ตัว กลางๆ ใส่ มา อย่าง 5 ตัว ปู สัก ตัว กำไร xxunk ตำ ทะเล ตำ กุ้ง สด 150 ไม่ แพง กุ้ง ชุ ป แป้ง ทอด แพง มาก ๆ ต้มยำ หม้อ ละ 300 ร้อย ถือว่า แพง มาก เพราะ มัน ใส่ ได้ ไม่ เยอะ หรอก มันดี ตรง ที่ มี น้ำ กับ ไฟ อุ่น ร้อน ของ กินใน บ้าน ยัง แทบ แตะ ไม่ได้ ทั้งที่ ป ระ ก็ xxunk คน ในประเทศ ยัง กิน ไม่ อิม ส่งออก นอก พอ มี น้อย เหลือ น้อย ก็ ขาย ให้ กัน แพง ๆ ระบบ แย่ เอาเปรียบ กันเอง ที่ บ้าน ขาย อาหาร กับข้าว ตาม สั่ง ป รุ่ง สุก ใหม่ แค่ จาน ละ 100 - 150 คน ยัง ว่า แพง ทั้งที่ บอ กว่า อร่อย ถ้า ไป เจอ แบบนี้ สงสัย ช็อค ตาย คา ร้าน เลย มัง ถ้า ต้อง ไป เจอ ทั้ง แพง ทั้ง ไม่อร่อย สัก แต่ ทำ ขาย ใคร ว่า ไม่ แพง ยินดี ด้วย ที่ คุณ เป็น คน มี ตัง แต่ เรา มอง จาก ค่าแรง กลางๆ ของ คน ในประเทศ นะ ซึ่ง ส่วนมาก คนใน ประเทศไทย ได้ แต่ ค่าแรงขั้นต่ำ กับ เบี้ย ขยัน เล็กน้อย คนจน เยอะ กว่า คนรวย ด้วย ทำ อะไร ต้อง นึกถึง ความ สมควร นึกถึง กันและกัน แต่ เรา ไม่ใช่ คน xxunk ชอบ มอง และ คิด จาก ความเป็นจริง ถึง ขาย ให้ ชาวต่างชาติ ก็ เถอะ เหมือน คนไทย เอาเปรียบ ช่วย โอกาส และ ไม่ ค่อย xxunk
y: LMLabelList
,,,,
Path: wisesight_data;
Test: None, model=SequentialRNN(
(0): AWD_LSTM(
(encoder): Embedding(15000, 400, padding_idx=1)
(encoder_dp): EmbeddingDropout(
(emb): Embedding(15000, 400, padding_idx=1)
)
(rnns): ModuleList(
(0): WeightDropout(
(module): LSTM(400, 1550, batch_first=True)
)
(1): WeightDropout(
(module): LSTM(1550, 1550, batch_first=True)
)
(2): WeightDropout(
(module): LSTM(1550, 1550, batch_first=True)
)
(3): WeightDropout(
(module): LSTM(1550, 400, batch_first=True)
)
)
(input_dp): RNNDropout()
(hidden_dps): ModuleList(
(0): RNNDropout()
(1): RNNDropout()
(2): RNNDropout()
(3): RNNDropout()
)
)
(1): LinearDecoder(
(decoder): Linear(in_features=400, out_features=15000, bias=True)
(output_dp): RNNDropout()
)
), opt_func=functools.partial(<class 'torch.optim.adam.Adam'>, betas=(0.9, 0.99)), loss_func=FlattenedLoss of CrossEntropyLoss(), metrics=[<function accuracy at 0x7f51be568268>], true_wd=True, bn_wd=True, wd=0.01, train_bn=True, path=PosixPath('wisesight_data'), model_dir='models', callback_fns=[functools.partial(<class 'fastai.basic_train.Recorder'>, add_time=True, silent=False), functools.partial(<class 'fastai.train.GradientClipping'>, clip=0.12)], callbacks=[RNNTrainer
learn: LanguageLearner(data=TextLMDataBunch;
Train: LabelList (23823 items)
x: LMTextList
xxbos ประเทศ เรา ผลิต และ ส่งออก ยาสูบ เยอะ สุด ใน โลก จิง ป่าว คับ,xxbos คะ,xxbos อิ เหี้ย ออม ทำ กู อยาก กิน เอ็ม เค,xxbos xxwrep 2 😅,xxbos สวัสดี วัน พุธ แนน อะไร นะ
y: LMLabelList
,,,,
Path: wisesight_data;
Valid: LabelList (240 items)
x: LMTextList
xxbos เห็น คน ลบ แอ พ viu ก็ เห็นใจ และ เข้าใจ เขา นะคะ แผล มัน ยัง ใหม่ แถม อารมณ์ ยิ่ง โดน xxunk ง่าย อยู่ นี่ เนอะ 5 xxrep 7 ส่วน ทาง นี้ ก็ กอด netflix แน่น มาก เธอ อย่า ทำร้าย เรา นะ เรา รู้ เธอ ไม่ ทำร้าย เรา แน่นอน,xxbos ไป ชม ไม้ คิว ของ แชมป์ และ รอง แชมป์ กัน จ้า ! . xxrep 32 เก็บตก จาก การแข่งขัน แสงโสม สนุกเกอร์ 6 แดง โอเพ่น ประจำปี 2560 สนาม ที่ 2 ณ มัง กี้ สนุกเกอร์ คลับ ซอย โชค ชัย 4 ลาดพร้าว เมื่อ วันที่ 12 ต.ค. 60,xxbos กลุ่ม รถ ซีวิค เป็น กลุ่ม ที่ น่า รำ คาน มาก xxrep 9 อวด รถ กัน ได้ ทุก วินาที อวด ทำไม มึง ก็ ใช้ รถ เหมือนกัน ทุกคน ละ ก็ พวก xxunk ที่ บอ กว่า อวด รถ แต่ ถ่าย นม ตัวเอง ชัด ละ รถ เบลอ นี่ คือ ? xxrep 5 ,xxbos อยาก สวย เหมือน เจ้าของ แบรนด์ สิ คะ เนย โชติ กา ใบหน้า สวย ใส xxunk แม้ แต่งหน้า นี่ ขนาด เป็น คุณแม่ แล้ว นะเนี่ย ก็ ยัง สวย ไม่ xxunk ผ่าน ไป กี่ ปี ๆ ก็ ไม่ เปลี่ยน ผิว ดี๊ ดี ความ สวย . เรา สร้าง เอง ได้ ด้วยตัวเอง ถ้า ได้ ใช้ มาส ์กโช ต้อง สวย เหมือน โชติ กา แน่นอน ค่ะ # มาส ์กโช สวย ข้ามคืน # cho _ cosmetics # daradaily # ดารา เดลี่,xxbos ข้าว โถ ละ ร้อย แพง เพราะ ตัก เป็น จาน ๆ ละ 15 เต็มที่ ก็ 5 จาน คนไทย ต้อง กินข้าว ประเทศ xxunk ข้าว กินข้าว ในประเทศ ตัวเอง หม้อ เป็น ร้อย เป็นลม ดีกว่า ค่า ฉะ xxunk ถุง 5 โล ไม่ เกิน 200 เป็น ข้าว มะลิ ไก่ นี่ ไม่รู้ ว่า เป็นตัว หรือเปล่า แต่ ถ้า ตัว ละ 250 บาท แพง ไก่ย่าง ขาย 140 - 160 มี เยอะแยะ ยัง ได้ กำไร แพง สุด ไม่ ควร xxunk 200 ข้าวผัด ปู จาน ใหญ่ 300 ร้อย แพง ถ้า ผัด เป็น จาน ๆ ละ 50 ผัด 4 จาน ก็ เต็ม ถาด ใหญ่ แล้ว ส่วน เครื่อง ดืม ด้านบน อะไร 80 ถ้า เป็น ชาเย็น แพง มาก น้ำ ดืม ขวด ใหญ่ ขวด ละ 50 แพง บ้าน เรา เมืองร้อน อย่า เห็นแก่ตัว 30 ก็ พอแล้ว คน ต้อง ซื้อ เยอะ เบียร์ ช้าง ขวด ละ 120 กำไร xxunk น่าเกลียด มา 3 ขวด 360 แพง xxunk ขวด ใหญ่ ก็ แพง แต่ น้ำแข็ง พอได้ เพราะ อากาศ บ้าน เรา ร้อน ละลาย ง่าย อันนี้ พอ เข้าใจ คน ขาย แต่ ทะเล เผา ทะเล ลวก ไม่เห็น หน้าตา ว่า มี อะไร บ้าง ก็ กุ้ง หมึก ปู xxunk 300 ตัว กลางๆ ใส่ มา อย่าง 5 ตัว ปู สัก ตัว กำไร xxunk ตำ ทะเล ตำ กุ้ง สด 150 ไม่ แพง กุ้ง ชุ ป แป้ง ทอด แพง มาก ๆ ต้มยำ หม้อ ละ 300 ร้อย ถือว่า แพง มาก เพราะ มัน ใส่ ได้ ไม่ เยอะ หรอก มันดี ตรง ที่ มี น้ำ กับ ไฟ อุ่น ร้อน ของ กินใน บ้าน ยัง แทบ แตะ ไม่ได้ ทั้งที่ ป ระ ก็ xxunk คน ในประเทศ ยัง กิน ไม่ อิม ส่งออก นอก พอ มี น้อย เหลือ น้อย ก็ ขาย ให้ กัน แพง ๆ ระบบ แย่ เอาเปรียบ กันเอง ที่ บ้าน ขาย อาหาร กับข้าว ตาม สั่ง ป รุ่ง สุก ใหม่ แค่ จาน ละ 100 - 150 คน ยัง ว่า แพง ทั้งที่ บอ กว่า อร่อย ถ้า ไป เจอ แบบนี้ สงสัย ช็อค ตาย คา ร้าน เลย มัง ถ้า ต้อง ไป เจอ ทั้ง แพง ทั้ง ไม่อร่อย สัก แต่ ทำ ขาย ใคร ว่า ไม่ แพง ยินดี ด้วย ที่ คุณ เป็น คน มี ตัง แต่ เรา มอง จาก ค่าแรง กลางๆ ของ คน ในประเทศ นะ ซึ่ง ส่วนมาก คนใน ประเทศไทย ได้ แต่ ค่าแรงขั้นต่ำ กับ เบี้ย ขยัน เล็กน้อย คนจน เยอะ กว่า คนรวย ด้วย ทำ อะไร ต้อง นึกถึง ความ สมควร นึกถึง กันและกัน แต่ เรา ไม่ใช่ คน xxunk ชอบ มอง และ คิด จาก ความเป็นจริง ถึง ขาย ให้ ชาวต่างชาติ ก็ เถอะ เหมือน คนไทย เอาเปรียบ ช่วย โอกาส และ ไม่ ค่อย xxunk
y: LMLabelList
,,,,
Path: wisesight_data;
Test: None, model=SequentialRNN(
(0): AWD_LSTM(
(encoder): Embedding(15000, 400, padding_idx=1)
(encoder_dp): EmbeddingDropout(
(emb): Embedding(15000, 400, padding_idx=1)
)
(rnns): ModuleList(
(0): WeightDropout(
(module): LSTM(400, 1550, batch_first=True)
)
(1): WeightDropout(
(module): LSTM(1550, 1550, batch_first=True)
)
(2): WeightDropout(
(module): LSTM(1550, 1550, batch_first=True)
)
(3): WeightDropout(
(module): LSTM(1550, 400, batch_first=True)
)
)
(input_dp): RNNDropout()
(hidden_dps): ModuleList(
(0): RNNDropout()
(1): RNNDropout()
(2): RNNDropout()
(3): RNNDropout()
)
)
(1): LinearDecoder(
(decoder): Linear(in_features=400, out_features=15000, bias=True)
(output_dp): RNNDropout()
)
), opt_func=functools.partial(<class 'torch.optim.adam.Adam'>, betas=(0.9, 0.99)), loss_func=FlattenedLoss of CrossEntropyLoss(), metrics=[<function accuracy at 0x7f51be568268>], true_wd=True, bn_wd=True, wd=0.01, train_bn=True, path=PosixPath('wisesight_data'), model_dir='models', callback_fns=[functools.partial(<class 'fastai.basic_train.Recorder'>, add_time=True, silent=False), functools.partial(<class 'fastai.train.GradientClipping'>, clip=0.12)], callbacks=[...], layer_groups=[Sequential(
(0): WeightDropout(
(module): LSTM(400, 1550, batch_first=True)
)
(1): RNNDropout()
), Sequential(
(0): WeightDropout(
(module): LSTM(1550, 1550, batch_first=True)
)
(1): RNNDropout()
), Sequential(
(0): WeightDropout(
(module): LSTM(1550, 1550, batch_first=True)
)
(1): RNNDropout()
), Sequential(
(0): WeightDropout(
(module): LSTM(1550, 400, batch_first=True)
)
(1): RNNDropout()
), Sequential(
(0): Embedding(15000, 400, padding_idx=1)
(1): EmbeddingDropout(
(emb): Embedding(15000, 400, padding_idx=1)
)
(2): LinearDecoder(
(decoder): Linear(in_features=400, out_features=15000, bias=True)
(output_dp): RNNDropout()
)
)], add_time=True, silent=False, cb_fns_registered=False)
alpha: 2
beta: 1], layer_groups=[Sequential(
(0): WeightDropout(
(module): LSTM(400, 1550, batch_first=True)
)
(1): RNNDropout()
), Sequential(
(0): WeightDropout(
(module): LSTM(1550, 1550, batch_first=True)
)
(1): RNNDropout()
), Sequential(
(0): WeightDropout(
(module): LSTM(1550, 1550, batch_first=True)
)
(1): RNNDropout()
), Sequential(
(0): WeightDropout(
(module): LSTM(1550, 400, batch_first=True)
)
(1): RNNDropout()
), Sequential(
(0): Embedding(15000, 400, padding_idx=1)
(1): EmbeddingDropout(
(emb): Embedding(15000, 400, padding_idx=1)
)
(2): LinearDecoder(
(decoder): Linear(in_features=400, out_features=15000, bias=True)
(output_dp): RNNDropout()
)
)], add_time=True, silent=False, cb_fns_registered=False)
[34]:
#train frozen
print("training frozen")
learn.freeze_to(-1)
learn.fit_one_cycle(1, 1e-2, moms=(0.8, 0.7))
training frozen
| epoch | train_loss | valid_loss | accuracy | time |
|---|---|---|---|---|
| 0 | 4.841187 | 4.462714 | 0.319742 | 02:47 |
[35]:
#train unfrozen
print("training unfrozen")
learn.unfreeze()
learn.fit_one_cycle(5, 1e-3, moms=(0.8, 0.7))
training unfrozen
| epoch | train_loss | valid_loss | accuracy | time |
|---|---|---|---|---|
| 0 | 4.411834 | 4.205552 | 0.341766 | 03:31 |
| 1 | 4.178030 | 4.037095 | 0.361508 | 03:31 |
| 2 | 3.970388 | 3.930919 | 0.370139 | 03:31 |
| 3 | 3.756190 | 3.890398 | 0.376191 | 03:31 |
| 4 | 3.671704 | 3.890232 | 0.375595 | 03:31 |
[ ]:
# learn.save('wisesight_lm')
learn.save_encoder("wisesight_enc")
Train Text Classifier
[39]:
#lm data
data_lm = load_data(model_path, "wisesight_lm.pkl")
data_lm.sanity_check()
#classification data
tt = Tokenizer(tok_func=ThaiTokenizer, lang="th", pre_rules=pre_rules_th, post_rules=post_rules_th)
processor = [TokenizeProcessor(tokenizer=tt, chunksize=10000, mark_fields=False),
NumericalizeProcessor(vocab=data_lm.vocab, max_vocab=60000, min_freq=20)]
data_cls = (ItemLists(model_path,train=TextList.from_df(train_df, model_path, cols=["texts"], processor=processor),
valid=TextList.from_df(valid_df, model_path, cols=["texts"], processor=processor))
.label_from_df("category")
.databunch(bs=50)
)
data_cls.sanity_check()
print(len(data_cls.vocab.itos))
15000
[40]:
#model
config = dict(emb_sz=400, n_hid=1550, n_layers=4, pad_token=1, qrnn=False,
output_p=0.4, hidden_p=0.2, input_p=0.6, embed_p=0.1, weight_p=0.5)
trn_args = dict(bptt=70, drop_mult=0.7, alpha=2, beta=1, max_len=500)
learn = text_classifier_learner(data_cls, AWD_LSTM, config=config, pretrained=False, **trn_args)
#load pretrained finetuned model
learn.load_encoder("wisesight_enc")
[40]:
RNNLearner(data=TextClasDataBunch;
Train: LabelList (20453 items)
x: TextList
xxbos กันแดด คิว เพลส ตัวใหม่ นี่ คุม มัน ดีจริง อ่ะ นี่ หน้า มัน ยิ่ง ที โซน ยิ่ง มัน เยอะ นีเวีย หลอด ยาว ๆ ฝา เขียว ก็ เอา ไม่อยู่ อ่ะ แล้ว xxunk,xxbos พบ กับ การ ร่วม ตัว ของ ศิลปิน soul pop สาม ยุค สาม สไตล์ ใน งาน jamnight อะไร ก็ช่าง xxunk ( ชุ่ย ) นำ ทีม โดย soul after six , the parkinson และ the xxup toys งาน นี้ นอกจาก จะ ได้ ดู โชว์ แบบ เต็ม รูปแบบ จาก ทั้ง สาม วง แล้ว ยัง มี โชว์ สุด พิเศษ ที่ ทั้ง สาม จะ ร่วม แจม กัน ด้วย ไม่ อยาก ให้ พลาด เจอกัน วันที่ 29 กันยายน นี้ ที่ ช่าง ชุ่ย ประตู เปิด 19.00 น. เป็นต้นไป สามารถ ซื้อ บัตร ได้ แล้ว ที่ event pop : http : / / go . eventpop . me / jamnight * จำกัด ผู้ ที่ มีอายุ 20 ปี ขึ้นไป # jamnightbyjameson # jamesonthailand # soulaftersix # theparkinson # thetoys,xxbos 👌 🏻 👌 🏻 👌 🏻 xxwrep 2 😆,xxbos จ - ศ แถม ถึง 29 ไม่ทัน มะ ว้า xxrep 4 ,xxbos ใช้ ดี ค่ะ บอกต่อ คือ เป็น คน แพ้ ง่าย มาก กก ใช้ กา นิ เย หรือ พอน ก็ แพ้ แต่ ใช้ ครีม แตงโม แล้ว คือ ดี สิว ลด กันน้ำ ค่ะ นี้ ใช้ ไป เล่น สงกรานต์ มา รอด ค่ะ 555 เล่อ ค่า xxrep 5
y: CategoryList
neg,neu,neu,neu,neg
Path: wisesight_data;
Valid: LabelList (3610 items)
x: TextList
xxbos เห็น คน ลบ แอ พ viu ก็ เห็นใจ และ เข้าใจ เขา นะคะ แผล มัน ยัง ใหม่ แถม อารมณ์ ยิ่ง โดน xxunk ง่าย อยู่ นี่ เนอะ 5 xxrep 7 ส่วน ทาง นี้ ก็ กอด netflix แน่น มาก เธอ อย่า ทำร้าย เรา นะ เรา รู้ เธอ ไม่ ทำร้าย เรา แน่นอน,xxbos ไป ชม ไม้ คิว ของ แชมป์ และ รอง แชมป์ กัน จ้า ! . xxrep 32 เก็บตก จาก การแข่งขัน แสงโสม สนุกเกอร์ 6 แดง โอเพ่น ประจำปี 2560 สนาม ที่ 2 ณ มัง กี้ สนุกเกอร์ คลับ ซอย โชค ชัย 4 ลาดพร้าว เมื่อ วันที่ 12 ต.ค. 60,xxbos กลุ่ม รถ ซีวิค เป็น กลุ่ม ที่ น่า รำ คาน มาก xxrep 9 อวด รถ กัน ได้ ทุก วินาที อวด ทำไม มึง ก็ ใช้ รถ เหมือนกัน ทุกคน ละ ก็ พวก xxunk ที่ บอ กว่า อวด รถ แต่ ถ่าย นม ตัวเอง ชัด ละ รถ เบลอ นี่ คือ ? xxrep 5 ,xxbos อยาก สวย เหมือน เจ้าของ แบรนด์ สิ คะ เนย โชติ กา ใบหน้า สวย ใส xxunk แม้ แต่งหน้า นี่ ขนาด เป็น คุณแม่ แล้ว นะเนี่ย ก็ ยัง สวย ไม่ xxunk ผ่าน ไป กี่ ปี ๆ ก็ ไม่ เปลี่ยน ผิว ดี๊ ดี ความ สวย . เรา สร้าง เอง ได้ ด้วยตัวเอง ถ้า ได้ ใช้ มาส ์กโช ต้อง สวย เหมือน โชติ กา แน่นอน ค่ะ # มาส ์กโช สวย ข้ามคืน # cho _ cosmetics # daradaily # ดารา เดลี่,xxbos ข้าว โถ ละ ร้อย แพง เพราะ ตัก เป็น จาน ๆ ละ 15 เต็มที่ ก็ 5 จาน คนไทย ต้อง กินข้าว ประเทศ xxunk ข้าว กินข้าว ในประเทศ ตัวเอง หม้อ เป็น ร้อย เป็นลม ดีกว่า ค่า ฉะ xxunk ถุง 5 โล ไม่ เกิน 200 เป็น ข้าว มะลิ ไก่ นี่ ไม่รู้ ว่า เป็นตัว หรือเปล่า แต่ ถ้า ตัว ละ 250 บาท แพง ไก่ย่าง ขาย 140 - 160 มี เยอะแยะ ยัง ได้ กำไร แพง สุด ไม่ ควร xxunk 200 ข้าวผัด ปู จาน ใหญ่ 300 ร้อย แพง ถ้า ผัด เป็น จาน ๆ ละ 50 ผัด 4 จาน ก็ เต็ม ถาด ใหญ่ แล้ว ส่วน เครื่อง ดืม ด้านบน อะไร 80 ถ้า เป็น ชาเย็น แพง มาก น้ำ ดืม ขวด ใหญ่ ขวด ละ 50 แพง บ้าน เรา เมืองร้อน อย่า เห็นแก่ตัว 30 ก็ พอแล้ว คน ต้อง ซื้อ เยอะ เบียร์ ช้าง ขวด ละ 120 กำไร xxunk น่าเกลียด มา 3 ขวด 360 แพง xxunk ขวด ใหญ่ ก็ แพง แต่ น้ำแข็ง พอได้ เพราะ อากาศ บ้าน เรา ร้อน ละลาย ง่าย อันนี้ พอ เข้าใจ คน ขาย แต่ ทะเล เผา ทะเล ลวก ไม่เห็น หน้าตา ว่า มี อะไร บ้าง ก็ กุ้ง หมึก ปู xxunk 300 ตัว กลางๆ ใส่ มา อย่าง 5 ตัว ปู สัก ตัว กำไร xxunk ตำ ทะเล ตำ กุ้ง สด 150 ไม่ แพง กุ้ง ชุ ป แป้ง ทอด แพง มาก ๆ ต้มยำ หม้อ ละ 300 ร้อย ถือว่า แพง มาก เพราะ มัน ใส่ ได้ ไม่ เยอะ หรอก มันดี ตรง ที่ มี น้ำ กับ ไฟ อุ่น ร้อน ของ กินใน บ้าน ยัง แทบ แตะ ไม่ได้ ทั้งที่ ป ระ ก็ xxunk คน ในประเทศ ยัง กิน ไม่ อิม ส่งออก นอก พอ มี น้อย เหลือ น้อย ก็ ขาย ให้ กัน แพง ๆ ระบบ แย่ เอาเปรียบ กันเอง ที่ บ้าน ขาย อาหาร กับข้าว ตาม สั่ง ป รุ่ง สุก ใหม่ แค่ จาน ละ 100 - 150 คน ยัง ว่า แพง ทั้งที่ บอ กว่า อร่อย ถ้า ไป เจอ แบบนี้ สงสัย ช็อค ตาย คา ร้าน เลย มัง ถ้า ต้อง ไป เจอ ทั้ง แพง ทั้ง ไม่อร่อย สัก แต่ ทำ ขาย ใคร ว่า ไม่ แพง ยินดี ด้วย ที่ คุณ เป็น คน มี ตัง แต่ เรา มอง จาก ค่าแรง กลางๆ ของ คน ในประเทศ นะ ซึ่ง ส่วนมาก คนใน ประเทศไทย ได้ แต่ ค่าแรงขั้นต่ำ กับ เบี้ย ขยัน เล็กน้อย คนจน เยอะ กว่า คนรวย ด้วย ทำ อะไร ต้อง นึกถึง ความ สมควร นึกถึง กันและกัน แต่ เรา ไม่ใช่ คน xxunk ชอบ มอง และ คิด จาก ความเป็นจริง ถึง ขาย ให้ ชาวต่างชาติ ก็ เถอะ เหมือน คนไทย เอาเปรียบ ช่วย โอกาส และ ไม่ ค่อย xxunk
y: CategoryList
neu,neu,neg,neu,neg
Path: wisesight_data;
Test: None, model=SequentialRNN(
(0): MultiBatchEncoder(
(module): AWD_LSTM(
(encoder): Embedding(15000, 400, padding_idx=1)
(encoder_dp): EmbeddingDropout(
(emb): Embedding(15000, 400, padding_idx=1)
)
(rnns): ModuleList(
(0): WeightDropout(
(module): LSTM(400, 1550, batch_first=True)
)
(1): WeightDropout(
(module): LSTM(1550, 1550, batch_first=True)
)
(2): WeightDropout(
(module): LSTM(1550, 1550, batch_first=True)
)
(3): WeightDropout(
(module): LSTM(1550, 400, batch_first=True)
)
)
(input_dp): RNNDropout()
(hidden_dps): ModuleList(
(0): RNNDropout()
(1): RNNDropout()
(2): RNNDropout()
(3): RNNDropout()
)
)
)
(1): PoolingLinearClassifier(
(layers): Sequential(
(0): BatchNorm1d(1200, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(1): Dropout(p=0.27999999999999997)
(2): Linear(in_features=1200, out_features=50, bias=True)
(3): ReLU(inplace)
(4): BatchNorm1d(50, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(5): Dropout(p=0.1)
(6): Linear(in_features=50, out_features=4, bias=True)
)
)
), opt_func=functools.partial(<class 'torch.optim.adam.Adam'>, betas=(0.9, 0.99)), loss_func=FlattenedLoss of CrossEntropyLoss(), metrics=[<function accuracy at 0x7f51be568268>], true_wd=True, bn_wd=True, wd=0.01, train_bn=True, path=PosixPath('wisesight_data'), model_dir='models', callback_fns=[functools.partial(<class 'fastai.basic_train.Recorder'>, add_time=True, silent=False)], callbacks=[RNNTrainer
learn: RNNLearner(data=TextClasDataBunch;
Train: LabelList (20453 items)
x: TextList
xxbos กันแดด คิว เพลส ตัวใหม่ นี่ คุม มัน ดีจริง อ่ะ นี่ หน้า มัน ยิ่ง ที โซน ยิ่ง มัน เยอะ นีเวีย หลอด ยาว ๆ ฝา เขียว ก็ เอา ไม่อยู่ อ่ะ แล้ว xxunk,xxbos พบ กับ การ ร่วม ตัว ของ ศิลปิน soul pop สาม ยุค สาม สไตล์ ใน งาน jamnight อะไร ก็ช่าง xxunk ( ชุ่ย ) นำ ทีม โดย soul after six , the parkinson และ the xxup toys งาน นี้ นอกจาก จะ ได้ ดู โชว์ แบบ เต็ม รูปแบบ จาก ทั้ง สาม วง แล้ว ยัง มี โชว์ สุด พิเศษ ที่ ทั้ง สาม จะ ร่วม แจม กัน ด้วย ไม่ อยาก ให้ พลาด เจอกัน วันที่ 29 กันยายน นี้ ที่ ช่าง ชุ่ย ประตู เปิด 19.00 น. เป็นต้นไป สามารถ ซื้อ บัตร ได้ แล้ว ที่ event pop : http : / / go . eventpop . me / jamnight * จำกัด ผู้ ที่ มีอายุ 20 ปี ขึ้นไป # jamnightbyjameson # jamesonthailand # soulaftersix # theparkinson # thetoys,xxbos 👌 🏻 👌 🏻 👌 🏻 xxwrep 2 😆,xxbos จ - ศ แถม ถึง 29 ไม่ทัน มะ ว้า xxrep 4 ,xxbos ใช้ ดี ค่ะ บอกต่อ คือ เป็น คน แพ้ ง่าย มาก กก ใช้ กา นิ เย หรือ พอน ก็ แพ้ แต่ ใช้ ครีม แตงโม แล้ว คือ ดี สิว ลด กันน้ำ ค่ะ นี้ ใช้ ไป เล่น สงกรานต์ มา รอด ค่ะ 555 เล่อ ค่า xxrep 5
y: CategoryList
neg,neu,neu,neu,neg
Path: wisesight_data;
Valid: LabelList (3610 items)
x: TextList
xxbos เห็น คน ลบ แอ พ viu ก็ เห็นใจ และ เข้าใจ เขา นะคะ แผล มัน ยัง ใหม่ แถม อารมณ์ ยิ่ง โดน xxunk ง่าย อยู่ นี่ เนอะ 5 xxrep 7 ส่วน ทาง นี้ ก็ กอด netflix แน่น มาก เธอ อย่า ทำร้าย เรา นะ เรา รู้ เธอ ไม่ ทำร้าย เรา แน่นอน,xxbos ไป ชม ไม้ คิว ของ แชมป์ และ รอง แชมป์ กัน จ้า ! . xxrep 32 เก็บตก จาก การแข่งขัน แสงโสม สนุกเกอร์ 6 แดง โอเพ่น ประจำปี 2560 สนาม ที่ 2 ณ มัง กี้ สนุกเกอร์ คลับ ซอย โชค ชัย 4 ลาดพร้าว เมื่อ วันที่ 12 ต.ค. 60,xxbos กลุ่ม รถ ซีวิค เป็น กลุ่ม ที่ น่า รำ คาน มาก xxrep 9 อวด รถ กัน ได้ ทุก วินาที อวด ทำไม มึง ก็ ใช้ รถ เหมือนกัน ทุกคน ละ ก็ พวก xxunk ที่ บอ กว่า อวด รถ แต่ ถ่าย นม ตัวเอง ชัด ละ รถ เบลอ นี่ คือ ? xxrep 5 ,xxbos อยาก สวย เหมือน เจ้าของ แบรนด์ สิ คะ เนย โชติ กา ใบหน้า สวย ใส xxunk แม้ แต่งหน้า นี่ ขนาด เป็น คุณแม่ แล้ว นะเนี่ย ก็ ยัง สวย ไม่ xxunk ผ่าน ไป กี่ ปี ๆ ก็ ไม่ เปลี่ยน ผิว ดี๊ ดี ความ สวย . เรา สร้าง เอง ได้ ด้วยตัวเอง ถ้า ได้ ใช้ มาส ์กโช ต้อง สวย เหมือน โชติ กา แน่นอน ค่ะ # มาส ์กโช สวย ข้ามคืน # cho _ cosmetics # daradaily # ดารา เดลี่,xxbos ข้าว โถ ละ ร้อย แพง เพราะ ตัก เป็น จาน ๆ ละ 15 เต็มที่ ก็ 5 จาน คนไทย ต้อง กินข้าว ประเทศ xxunk ข้าว กินข้าว ในประเทศ ตัวเอง หม้อ เป็น ร้อย เป็นลม ดีกว่า ค่า ฉะ xxunk ถุง 5 โล ไม่ เกิน 200 เป็น ข้าว มะลิ ไก่ นี่ ไม่รู้ ว่า เป็นตัว หรือเปล่า แต่ ถ้า ตัว ละ 250 บาท แพง ไก่ย่าง ขาย 140 - 160 มี เยอะแยะ ยัง ได้ กำไร แพง สุด ไม่ ควร xxunk 200 ข้าวผัด ปู จาน ใหญ่ 300 ร้อย แพง ถ้า ผัด เป็น จาน ๆ ละ 50 ผัด 4 จาน ก็ เต็ม ถาด ใหญ่ แล้ว ส่วน เครื่อง ดืม ด้านบน อะไร 80 ถ้า เป็น ชาเย็น แพง มาก น้ำ ดืม ขวด ใหญ่ ขวด ละ 50 แพง บ้าน เรา เมืองร้อน อย่า เห็นแก่ตัว 30 ก็ พอแล้ว คน ต้อง ซื้อ เยอะ เบียร์ ช้าง ขวด ละ 120 กำไร xxunk น่าเกลียด มา 3 ขวด 360 แพง xxunk ขวด ใหญ่ ก็ แพง แต่ น้ำแข็ง พอได้ เพราะ อากาศ บ้าน เรา ร้อน ละลาย ง่าย อันนี้ พอ เข้าใจ คน ขาย แต่ ทะเล เผา ทะเล ลวก ไม่เห็น หน้าตา ว่า มี อะไร บ้าง ก็ กุ้ง หมึก ปู xxunk 300 ตัว กลางๆ ใส่ มา อย่าง 5 ตัว ปู สัก ตัว กำไร xxunk ตำ ทะเล ตำ กุ้ง สด 150 ไม่ แพง กุ้ง ชุ ป แป้ง ทอด แพง มาก ๆ ต้มยำ หม้อ ละ 300 ร้อย ถือว่า แพง มาก เพราะ มัน ใส่ ได้ ไม่ เยอะ หรอก มันดี ตรง ที่ มี น้ำ กับ ไฟ อุ่น ร้อน ของ กินใน บ้าน ยัง แทบ แตะ ไม่ได้ ทั้งที่ ป ระ ก็ xxunk คน ในประเทศ ยัง กิน ไม่ อิม ส่งออก นอก พอ มี น้อย เหลือ น้อย ก็ ขาย ให้ กัน แพง ๆ ระบบ แย่ เอาเปรียบ กันเอง ที่ บ้าน ขาย อาหาร กับข้าว ตาม สั่ง ป รุ่ง สุก ใหม่ แค่ จาน ละ 100 - 150 คน ยัง ว่า แพง ทั้งที่ บอ กว่า อร่อย ถ้า ไป เจอ แบบนี้ สงสัย ช็อค ตาย คา ร้าน เลย มัง ถ้า ต้อง ไป เจอ ทั้ง แพง ทั้ง ไม่อร่อย สัก แต่ ทำ ขาย ใคร ว่า ไม่ แพง ยินดี ด้วย ที่ คุณ เป็น คน มี ตัง แต่ เรา มอง จาก ค่าแรง กลางๆ ของ คน ในประเทศ นะ ซึ่ง ส่วนมาก คนใน ประเทศไทย ได้ แต่ ค่าแรงขั้นต่ำ กับ เบี้ย ขยัน เล็กน้อย คนจน เยอะ กว่า คนรวย ด้วย ทำ อะไร ต้อง นึกถึง ความ สมควร นึกถึง กันและกัน แต่ เรา ไม่ใช่ คน xxunk ชอบ มอง และ คิด จาก ความเป็นจริง ถึง ขาย ให้ ชาวต่างชาติ ก็ เถอะ เหมือน คนไทย เอาเปรียบ ช่วย โอกาส และ ไม่ ค่อย xxunk
y: CategoryList
neu,neu,neg,neu,neg
Path: wisesight_data;
Test: None, model=SequentialRNN(
(0): MultiBatchEncoder(
(module): AWD_LSTM(
(encoder): Embedding(15000, 400, padding_idx=1)
(encoder_dp): EmbeddingDropout(
(emb): Embedding(15000, 400, padding_idx=1)
)
(rnns): ModuleList(
(0): WeightDropout(
(module): LSTM(400, 1550, batch_first=True)
)
(1): WeightDropout(
(module): LSTM(1550, 1550, batch_first=True)
)
(2): WeightDropout(
(module): LSTM(1550, 1550, batch_first=True)
)
(3): WeightDropout(
(module): LSTM(1550, 400, batch_first=True)
)
)
(input_dp): RNNDropout()
(hidden_dps): ModuleList(
(0): RNNDropout()
(1): RNNDropout()
(2): RNNDropout()
(3): RNNDropout()
)
)
)
(1): PoolingLinearClassifier(
(layers): Sequential(
(0): BatchNorm1d(1200, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(1): Dropout(p=0.27999999999999997)
(2): Linear(in_features=1200, out_features=50, bias=True)
(3): ReLU(inplace)
(4): BatchNorm1d(50, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(5): Dropout(p=0.1)
(6): Linear(in_features=50, out_features=4, bias=True)
)
)
), opt_func=functools.partial(<class 'torch.optim.adam.Adam'>, betas=(0.9, 0.99)), loss_func=FlattenedLoss of CrossEntropyLoss(), metrics=[<function accuracy at 0x7f51be568268>], true_wd=True, bn_wd=True, wd=0.01, train_bn=True, path=PosixPath('wisesight_data'), model_dir='models', callback_fns=[functools.partial(<class 'fastai.basic_train.Recorder'>, add_time=True, silent=False)], callbacks=[...], layer_groups=[Sequential(
(0): Embedding(15000, 400, padding_idx=1)
(1): EmbeddingDropout(
(emb): Embedding(15000, 400, padding_idx=1)
)
), Sequential(
(0): WeightDropout(
(module): LSTM(400, 1550, batch_first=True)
)
(1): RNNDropout()
), Sequential(
(0): WeightDropout(
(module): LSTM(1550, 1550, batch_first=True)
)
(1): RNNDropout()
), Sequential(
(0): WeightDropout(
(module): LSTM(1550, 1550, batch_first=True)
)
(1): RNNDropout()
), Sequential(
(0): WeightDropout(
(module): LSTM(1550, 400, batch_first=True)
)
(1): RNNDropout()
), Sequential(
(0): PoolingLinearClassifier(
(layers): Sequential(
(0): BatchNorm1d(1200, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(1): Dropout(p=0.27999999999999997)
(2): Linear(in_features=1200, out_features=50, bias=True)
(3): ReLU(inplace)
(4): BatchNorm1d(50, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(5): Dropout(p=0.1)
(6): Linear(in_features=50, out_features=4, bias=True)
)
)
)], add_time=True, silent=False, cb_fns_registered=False)
alpha: 2
beta: 1], layer_groups=[Sequential(
(0): Embedding(15000, 400, padding_idx=1)
(1): EmbeddingDropout(
(emb): Embedding(15000, 400, padding_idx=1)
)
), Sequential(
(0): WeightDropout(
(module): LSTM(400, 1550, batch_first=True)
)
(1): RNNDropout()
), Sequential(
(0): WeightDropout(
(module): LSTM(1550, 1550, batch_first=True)
)
(1): RNNDropout()
), Sequential(
(0): WeightDropout(
(module): LSTM(1550, 1550, batch_first=True)
)
(1): RNNDropout()
), Sequential(
(0): WeightDropout(
(module): LSTM(1550, 400, batch_first=True)
)
(1): RNNDropout()
), Sequential(
(0): PoolingLinearClassifier(
(layers): Sequential(
(0): BatchNorm1d(1200, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(1): Dropout(p=0.27999999999999997)
(2): Linear(in_features=1200, out_features=50, bias=True)
(3): ReLU(inplace)
(4): BatchNorm1d(50, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(5): Dropout(p=0.1)
(6): Linear(in_features=50, out_features=4, bias=True)
)
)
)], add_time=True, silent=False, cb_fns_registered=False)
[ ]:
# #train unfrozen
# learn.freeze_to(-1)
# learn.fit_one_cycle(1, 2e-2, moms=(0.8, 0.7))
# learn.freeze_to(-2)
# learn.fit_one_cycle(1, slice(1e-2 / (2.6 ** 4), 1e-2), moms=(0.8, 0.7))
# learn.freeze_to(-3)
# learn.fit_one_cycle(1, slice(5e-3 / (2.6 ** 4), 5e-3), moms=(0.8, 0.7))
# learn.unfreeze()
# learn.fit_one_cycle(10, slice(1e-3 / (2.6 ** 4), 1e-3), moms=(0.8, 0.7),
# callbacks=[SaveModelCallback(learn, every='improvement', monitor='accuracy', name='bestmodel')])
Training takes about 20 minutes so we use the script train_model.py to do it with the following results (validation run):
epoch train_loss valid_loss accuracy
1 0.812156 0.753478 0.687532
Total time: 00:56
epoch train_loss valid_loss accuracy
1 0.740403 0.699093 0.714394
Total time: 00:57
epoch train_loss valid_loss accuracy
1 0.727394 0.668807 0.723011
Total time: 01:34
epoch train_loss valid_loss accuracy
1 0.722163 0.675351 0.723517
2 0.675266 0.654477 0.738723
3 0.669178 0.641070 0.737962
4 0.612528 0.637456 0.744551
5 0.618259 0.635149 0.749366
6 0.572621 0.651169 0.749873
7 0.561985 0.661739 0.747593
8 0.534753 0.673563 0.738469
9 0.530844 0.688871 0.746072
10 0.522788 0.670024 0.743031
Total time: 23:42
See Results
[ ]:
learn.load("bestmodel")
#get predictions
probs, y_true, loss = learn.get_preds(ds_type = DatasetType.Valid, ordered=True, with_loss=True)
classes = learn.data.train_ds.classes
y_true = np.array([classes[i] for i in y_true.numpy()])
preds = np.array([classes[i] for i in probs.argmax(1).numpy()])
prob = probs.numpy()
loss = loss.numpy()
[ ]:
to_df = np.concatenate([y_true[:,None],preds[:,None],loss[:,None],prob],1)
probs_df = pd.DataFrame(to_df)
probs_df.columns = ["category","preds","loss"] + classes
probs_df["hit"] = (probs_df.category == probs_df.preds)
probs_df["texts"] = valid_df.texts
(y_true==preds).mean()
0.8392661555312158
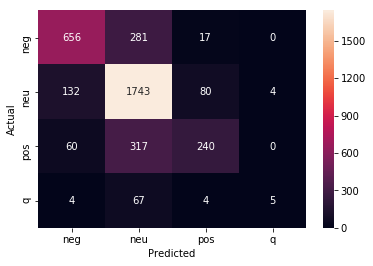
[ ]:
from sklearn.metrics import confusion_matrix
import seaborn as sns
conf_mat = confusion_matrix(probs_df.category,probs_df.preds)
sns.heatmap(conf_mat, annot=True, fmt="d",
xticklabels=classes, yticklabels=classes)
plt.ylabel("Actual")
plt.xlabel("Predicted")
plt.show()